정미나닷컴
[Oracle] 오라클 인덱스 정상적인 사용이 불가능한 경우, 튜닝 방안 본문
쿼리의 조건절에 인덱스 선두 컬럼이 사용된 경우(인덱스가 B*Tree 형태일 때)
옵티마이저는 인덱스의 Root부터 탐색을 시작해 Branch를 거쳐 원하는 레코드 키값이 존재하는 Leaf 까지 도달한다.
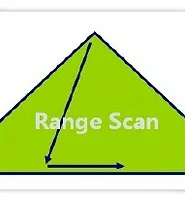
이 때 Root -> Branch -> Leaf 에 도달하는 과정(Leaf node의 시작점을 찾는 과정)을 수직적 탐색,
Leaf node의 시작점에서부터 원하는 범위까지를 scan하는 과정(인덱스는 정렬 상태이므로)을 수평적 탐색,
수평적 탐색을 통해 get한 RowID를 이용해 궁극적으로 원하는 데이터가 있는(Select 절에 명시된 컬럼 데이터) 테이블까지 도달하는 과정을 Table Random Access라고 한다.

하지만 주의해야 할 점은 조건절에 인덱스 컬럼을 사용한다고 해서 무조건 인덱스 활용이 가능하지는 않다는 것이다.
인덱스 활용이 불가능하거나 범위 스캔이 불가능한 경우
- 인덱스 컬럼의 가공 (좌변 가공)
SELECT *
FROM TEVENT
WHERE SUBSTR(EVENT_NAME, 1, 2) = '추석';
-- 인덱스 스캔은 인덱스 키값이 기준인데 그 기준이 변해버리니 말짱 황
-- FBI(미국 FBI아니고 Function Based Index)를 SUBSTR(EVENT_NAME, 1, 2)로 생성하면 활용 가능하긴 하지만 굳이;
-- 튜닝 방안: WHERE EVENT_NAME LIKE '추석%'
-- but!! '%'가 앞에 붙은 LIKE는 인덱스 활용이 불가능하므로 SUBSTR(EVENT_NAME, 4, 2) = '송편' 같은 경우는 해당 X
-- INDEX FULL SCAN은 가능
SELECT *
FROM TORDER
WHERE NVL(ORDER_CNT, 0) >= 100;
-- ORDER_CNT가 NULL인 경우는 어차피 결과집합에 포함되지 않음
-- 튜닝 방안: WHERE ORDER_CNT >= 100;
-- 애초에 테이블 설계 시 ORDER_CNT 컬럼의 Default값을 0으로 지정하는게 좋음
- 부정형 비교
SELECT *
FROM TEVENT
WHERE EVENT_TYPE <> '20';
-- 튜닝 방안: WHERE EVENT_TYPE IN ('10', '30'); // EVENT_TYPE이 '10', '20', '30'인 경우
-- INDEX FULL SCAN은 가능
- IS NOT NULL 조건
SELECT *
FROM TEVENT
WHERE EVENT_SDATE IS NOT NULL;
-- INDEX FULL SCAN은 가능
-- 단일 컬럼 인덱스일 경우: 오라클 인덱스는 NULL값은 저장하지 않기 때문에 인덱스 전체 레코드가 모두 조건 만족
-- 결합 인덱스일 경우: 인덱스 구성 컬럼 중 하나라도 NULL값이 아닌 레코드는 저장, INDEX FULL SCAN 하면서 필터링
- IS NULL 조건
SELECT *
FROM TEVENT
WHERE EVENT_SDATE IS NULL;
-- 인덱스 사용 불가능
-- 단일 컬럼 인덱스일 경우: 저장이 안되어 있음
-- 결합 인덱스일 경우: 모든 인덱스 구성 컬럼이 NULL값인 경우는 저장이 안되어 있음
-- 다른 인덱스 구성 컬럼 중 어느 하나에 NOT NULL 제약이 걸려있다면 무조건 INDEX RANGE SCAN 가능
-- 다른 인덱스 구성 컬럼에 IS NULL 이외의 조건식이 있으면 INDEX RANGE SCAN 가능(둘 중 하나가 선두 컬럼일 때)
-- ex) WHERE EVENT_SDATE IS NULL AND EVENT_TYPE = '10';
-- 만약 EVENT_SDATE가 인덱스 선두 컬럼이라면 맨 뒤에 NULL값이 저장되는 곳부터 SCAN
- 묵시적 형변환
SELECT *
FROM TEVENT
WHERE EVENT_SDATE = SUBSTR( :사용자입력일자, 1, 6 ) - 1; -- EVENT_SDATE 컬럼은 VARCHAR2
-- 내부적 변환 과정 => WHERE TO_NUMBER(EVENT_SDATE) = TO_NUMBER(SUBSTR( :사용자입력일자, 1, 6 )) - 1
-- 결과적으로 좌변 가공이 되어버림
-- 튜닝 방안: WHERE EVENT_SDATE = TO_CHAR(ADD_MONTHS(TO_DATE( :사용자입력일자, 'YYYYMMDD'), -1), 'YYYYMM')
* 묵시적 형변환은 성능 측면에서는 물론이고 쿼리 수행 도중 에러가 발생하거나 틀린 결과를 불러올 수도 있기 때문에 무조건 쓰지 않도록 한다. (명시적으로 변환 함수를 사용하는게 바람직)
튜닝 사례 1
일별지수업종별거래및시세_PK : 지수구분코드 + 지수업종코드 + 거래일자
일별지수업종별거래및시세_X01 : 거래일자
SELECT ~~~~~~~
FROM 일별지수업종별거래및시세 A
WHERE 거래일자 BEWEEN :startDd AND :endDd
AND 지수구분코드 || 지수업종코드 IN ('1001','2003')
-- 지수구분코드가 '1'이면서 지수업종코드가 '001'이거나 지수구분코드가 '2'이면서 지수업종코드가 '003'
GROUP BY 거래일자;
-- 튜닝 방안: AND (지수구분코드, 지수업종코드) IN ( ('1', '001'), ('2', '003') )
튜닝 사례 2
접수정보파일_PK : 수신번호
접수정보파일_X01 : 정정대상접수번호 + 금감원접수번호
SELECT *
FROM 접수정보파일
WHERE DECODE(정정대상접수번호, LPAD(' ', 14), 금감원접수번호, 정정대상접수번호) = :접수번호;
-- 정정대상접수번호가 14자리의 공백문자이면 금감원접수번호가, 아니면 정정대상접수번호가 :접수번호와 같은 레코드
-- LPAD(' ', 14)를 사용한 걸로 봐서 정정대상접수번호 컬럼의 TYPE은 CHAR 형으로 추측됨
-- 튜닝 방안: WHERE 정정대상접수번호 IN ( :접수번호, LPAD(' ', 14) )
AND 금감원접수번호 = DECODE(정정대상접수번호, LPAD(' ', 14), :접수번호, 금감원접수번호)
'IT' 카테고리의 다른 글
| [Oracle] 오라클 Nested Loops JOIN, NL 조인 (0) | 2017.09.22 |
|---|---|
| [Oracle] 오라클 인덱스 스캔 방식 (0) | 2017.09.17 |
| [Oracle] 오라클 인덱스 구조 - B*Tree Index (0) | 2017.09.14 |
| [Oracle] 오라클 에러 ORA-06502: PL/SQL: 수치 또는 값 오류: 문자열 버퍼가 너무 작습니다 (0) | 2017.09.04 |
| [Java] 자바 String, Date, Calendar 형변환 (0) | 2016.10.26 |